
 岩猫星空网
岩猫星空网
大多数人可能不知道,Scaling law 原始研究来自 2017 年的百度,而非三年后(2020 年)的 OpenAI。此研究由吴恩达主持,来自百度硅谷人工智能实验室 (SVAIL) 系统团队。
via https://x.com/jxmnop/status/1861473014673797411
Anthropic的创始团队是GPT系列产品的早期开发者,达里奥·阿莫迪则曾是OpenAI研究副总裁。2014年达里奥·阿莫迪从斯坦福博士后毕业后加入百度硅谷人工智能实验室(SVAIL),致力于将深度学习模型扩展到大规模高性能计算系统,一直到2015年10月离开。
百度硅谷人工智能实验室团队在2017年12月发表了名为《Deep Learning Scaling Is Predictable,Empirically》(《经验表明深度学习是可预测的》)的论文,详细讨论了机器翻译、语言建模等领域的Scaling现象。
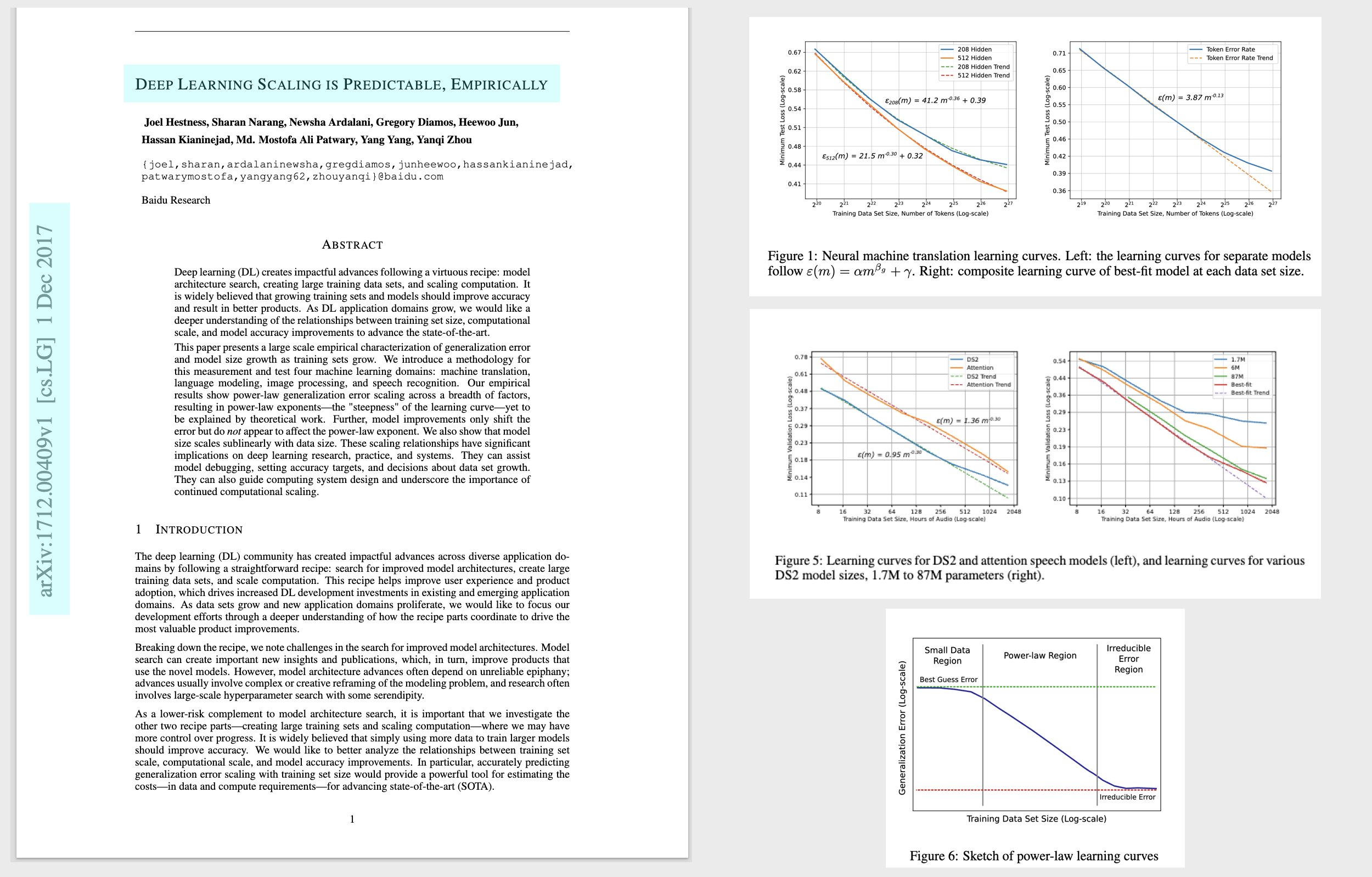
但这篇论文的重要性严重被忽视了。OpenAI在其2019年的Scaling Law研究论文中,引述了上述百度论文第一作者Joel Hestness在2019年的后续研究,他曾于2017年~2019年在百度工作。
不过,正是因为对Scaling Law的早期研究,使得百度多年前便投入了AI大模型研究,并在2019年发布了第一代文心大模型。
那一年,OpenAI亦推出了GPT-1。可见百度和OpenAI等知名AI公司站在同一起跑线甚至跑得更早。
当然,这也使得百度成为全球第一家推出生成式AI产品的科技大厂。
更多独家技术见解与热门话题讨论,尽在【开源中国 APP】,与数百万开发者一起,随时随地探索技术无限可能。
未经允许不得转载:岩猫星空网 » 百度最早提出 Scaling Law







