
 岩猫星空网
岩猫星空网
11 月 28 日,阿里云通义团队发布全新 AI 推理模型 QwQ-32B-Preview,并同步开源。评测数据显示,预览版本的 QwQ,已展现出研究生水平的科学推理能力,在数学和编程方面表现尤为出色,整体推理水平比肩 OpenAI o1。
QwQ(Qwen with Questions)是通义千问 Qwen 大模型最新推出的实验性研究模型,也是阿里云首个开源的 AI 推理模型。阿里云通义千问团队研究发现,当模型有足够的时间思考、质疑和反思时,其对数学和编程的理解就会深化。基于此,QwQ 取得了解决复杂问题的突破性进展。
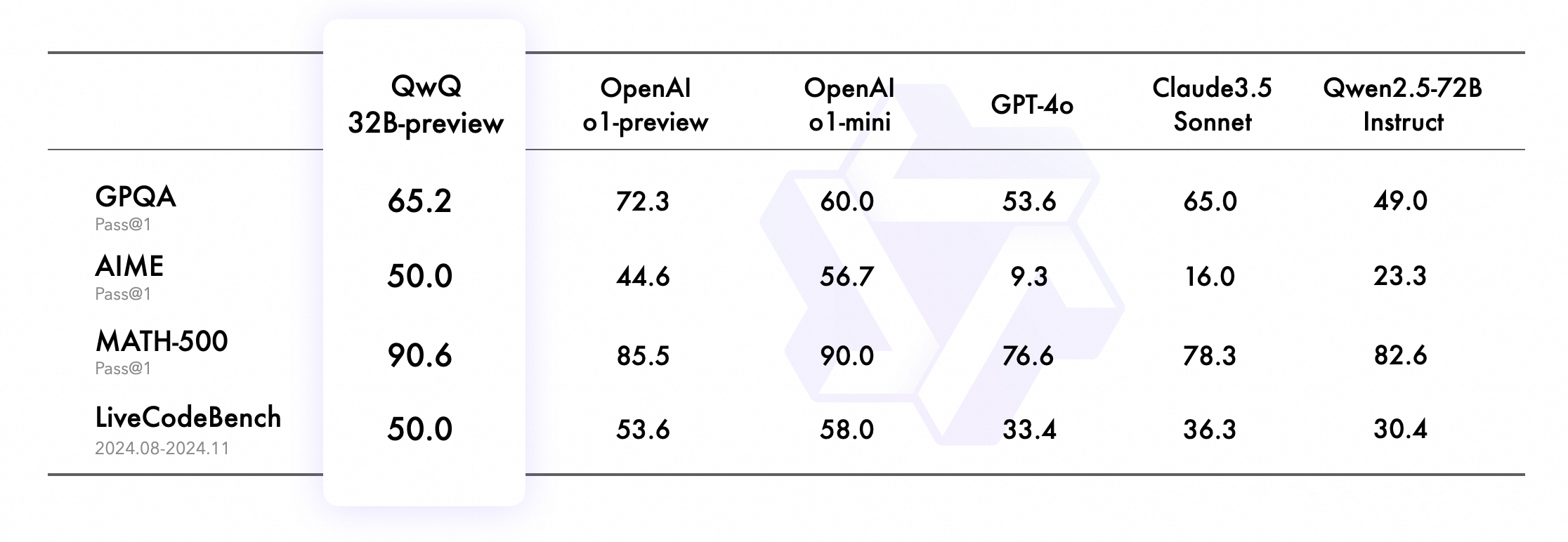
在考察科学问题解决能力的 GPQA 评测集上,QwQ 获得 65.2% 的准确率,具备研究生水平的科学推理能力;在涵盖综合数学主题的 AIME 评测中,QwQ 以 50% 的胜率证明其拥有解决数学问题的丰富技能;在全面考察数学解题能力的 MATH-500 评测中,QwQ 斩获 90.6% 的高分,一举超越 o1-preview 和 o1-mini;在评估高难度代码生成的 LiveCodeBench 评测中,QwQ 答对一半的题,在编程竞赛题场景中也有出色表现。
面对复杂问题,QwQ 展现了深度自省的能力,会质疑自身假设,进行深思熟虑的自我对话,并仔细审视其推理过程的每一步。比如,在经典智力题「猜牌问题」中,QwQ 通过梳理各方对话并推演现实情况,像个擅长思考的人一样,揣摩「这句话有点 tricky」,反思「等一下,也许我需要更仔细地思考」,最终分析得出正确答案,让人惊艳。
目前,QwQ-32B-Preview 已在魔搭社区和 HuggingFace 等平台上开源。发布短短几小时,引起全球开发者热情体验。有开发者认为该模型「是完全没有预料到的疯狂的跃进」、「今年开源领域最重大的突破」、「让中国在开源大模型和 AI 推理上占据先机」。
通义团队透露,尽管 QwQ 展现了强大的分析能力,但该模型仍是个供研究的实验型模型,存在不同语言的混合使用、偶有不恰当偏见、对专业领域问题不了解等局限。随着研究深入模型迭代,这些问题将逐步得到解决。
附:
未经允许不得转载:岩猫星空网 » 通义开源推理大模型 QwQ,推理水平比肩 OpenAI o1







