岩猫星空网
岩猫星空网
2024 年 11 月 13 日,RWKV-6-World-7B-v3 模型正式开源发布。
对比 RWKV-6-World-v2.1 模型,RWKV-6-World-v3 模型新增了 World-v3 数据集(约 3.1T tokens),对比 v2.1 数据集补充了优质英文网页、代码、中文小说、多语言数据、数学数据、指令数据等。
更多的训练数据带来更好的模型性能,RWKV-6-World-7B-v3 的各方面能力显著增强,包括中文小说、对话、代码、数学能力。
RWKV-World 是 RWKV 模型的全球多语言训练数据集, World 数据集的每个版本号对应不同的数据量:
- World v1 ≈ 0.59T tokens
- World v2 数据集 ≈ 1.12T tokens,v2 模型的总训练数据 ≈ 1.12T tokens
- World v2.1 数据集约 1.4T tokens, v2.1 模型的总训练数据是 v2(1.12T)+ v2.1(1.4T)≈2.5T tokens
- World v3 数据集约 3.1T tokens, v3 模型的总训练数据是 v2(1.12T)+ v2.1(1.4T)+ v3(3.1T) ≈ 5.6T tokens
新模型的评测数据
我们对新模型进行了英文和多语言测评、MMLU 评测和 Uncheatable Eval 评测。
v3 数据集增加了 0.2T 代码,RWKV-6-World-7B-v3 在各项评测中的代码成绩都有所改善,我们后续会显著增加更多的代码数据。
英文和多语言评测
本次模型基准测试涵盖了 RWKV 和 Llama 两个系列,共 5 款 7B 参数规模的开源模型。
我们选取了 12 个独立的基准测试,衡量大模型在常识推理和世界知识等英语内容上的表现。多语言能力的评估则采用了 xLAMBDA、xStoryCloze、 xWinograd 和 xCopa 四种基准测试,深度评估模型在多语言环境中的逻辑推理、故事理解、歧义解决和因果推理能力。

可以看到,相比于此前发布的 RWKV-6-World-7B-v2.1 模型,RWKV-6-World-7B-v3 的英文和多语言能力都有显著提升。在英文能力方面,RWKV-6-World-7B-v3 缩小了与使用 15T 数据训练的 Llama3 的差距。在多语言能力方面,继续扩大了在同参数模型的领先地位。
此外,RWKV-6-World-7B-v3 的 MMLU 评测准确率为 54.2%。作为对比,RWKV-6-7B-World-v2.1 的 MMLU 分数为 47.9%。注意:我们没有使用”刷榜技巧”去增强各项成绩。
Uncheatable Eval 评测
我们对 RWKV-6-World-7B-v3 模型进行了 “无法作弊的模型评测” —— Uncheatable Eval。
Uncheatable Eval 会使用最新的 arXiv 论文和新闻文章等实时语料库,以此来评估语言模型的真实建模能力和泛化能力。 详情请参见 RWKV在“不可作弊的模型评测”中获得良好成绩
Uncheatable Eval 评测的分数越低,意味着模型性能越好。
最新的 Uncheatable Eval 评测选取了常见的 15 款开源 7B 参数模型,测评数据则选择 最新发布的 arXiv 论文、新闻、ao3 中英文小说和 GitHub 代码等实时数据。具体评分和综合排名如下:
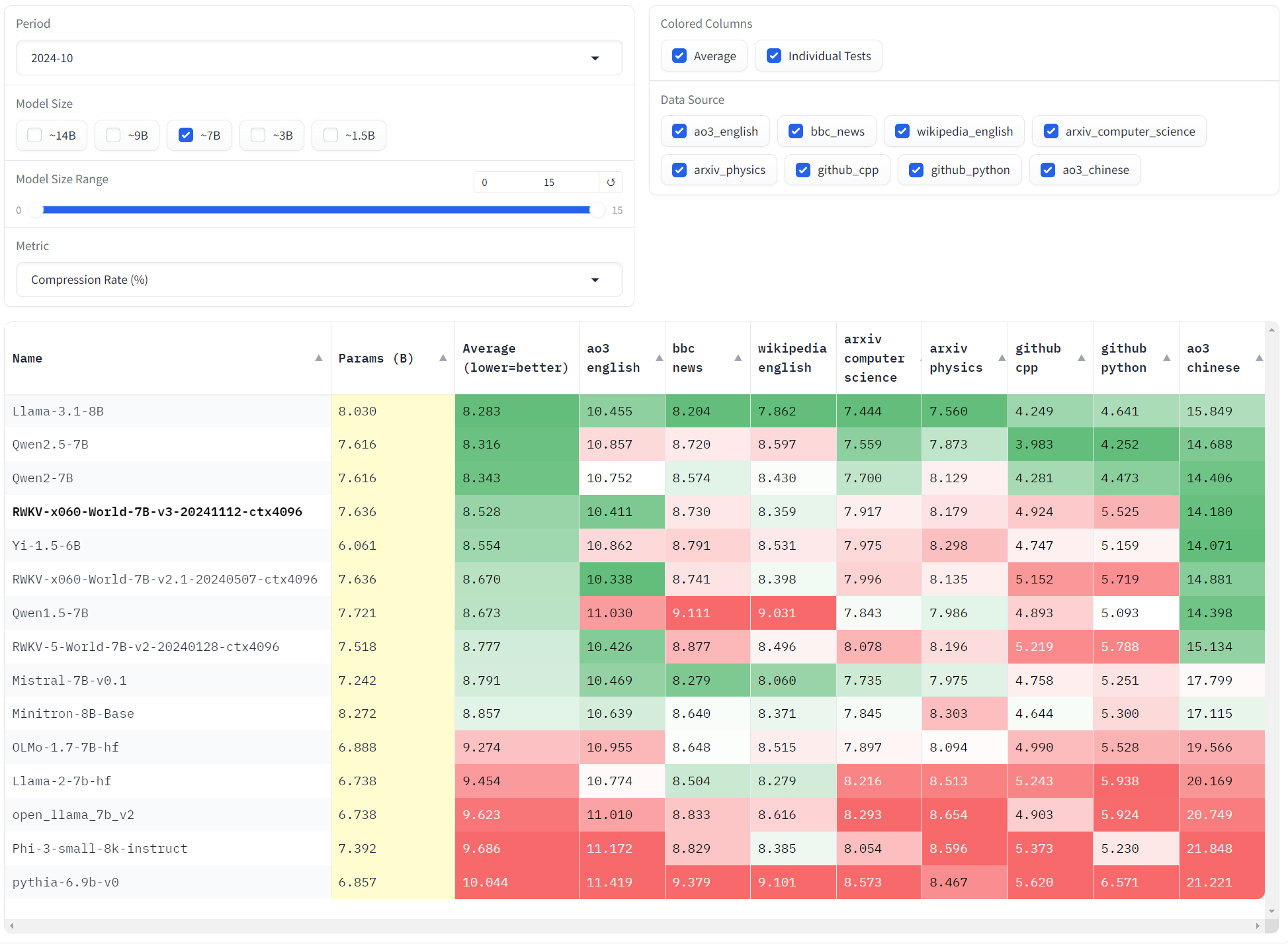
可以看到,RWKV-6-World-7B-v3 在同等参数下的英文数据建模能力超越了大多数模型,仅逊于 Llama3.1、Qwen、Mistral 等训练数据较多的模型。
注意 RWKV-6-World 系列的多语言能力显著胜于这些模型,尤其是小语种能力。例如,在中文小说(ao3 chinese)方面,RWKV-6-7B-v3的成绩是 14.180,显著胜于 RWKV-6-7B-v2.1 的 14.881,和 Qwen2-7B 的 14.406。
我们也在继续补充 RWKV 模型的训练数据,向表现更好的模型看齐。RWKV-7-World-v4 版本预计将实现全面领先。
v3 数据集包含 0.1T 中文小说数据,这使得 RWKV-6-World-7B-v3 中文小说能力得到了显著增强,但同时也影响到其它性能指标。
例如,我们发现中文小说数据对 v3 模型在英语小说上的性能评测有负面影响。
在以英文小说阅读理解为主的 LAMBADA 和 ReCoRD 测试中,RWKV-6-World-7B-v3 的表现比 RWKV-6-World-7B-v2.1 略低。 而在 Uncheatable Eval 评测中,RWKV-6-World-7B-v3 的 ao3 english 英文小说评测表现也略逊于 RWKV-6-World-7B-v2.1 模型。
模型下载和体验
可以在以下在线 Demo 中体验 RWKV-6-World-7B-v3 模型:
在线 Demo 限制了最大输入长度为 1536 字。
也可以从以下平台下载 RWKV-6-World-7B-v3 模型,并进行本地部署:
本地部署 RWKV 模型
推荐使用 RWKV Runner 或 Ai00 本地部署 RWKV 模型,RWKV 模型也支持 llama.cpp 推理 。
::: block-3 运行 RWKV-6-World-7B-v3 模型时,请勿搭载基于 RWKV-6-World-v2.1 等旧模型训练的 state 文件。
请使用最新发布的 RWKV-6-7B v3 state 文件:https://huggingface.co/BlinkDL/rwkv-6-misc/tree/main/states :::
本地部署的显存需求
如果你计划本地部署并推理 RWKV-6-World-7B-v3 模型,参考的 VRAM (显存)消耗如下:
*以上配置默认满层量化
新模型效果预览
以下为 RWKV-6-World-7B-v3 模型的实测效果:
以下案例使用 Ai00 作为推理服务器,int8 + 30 层量化,未加载任何 State
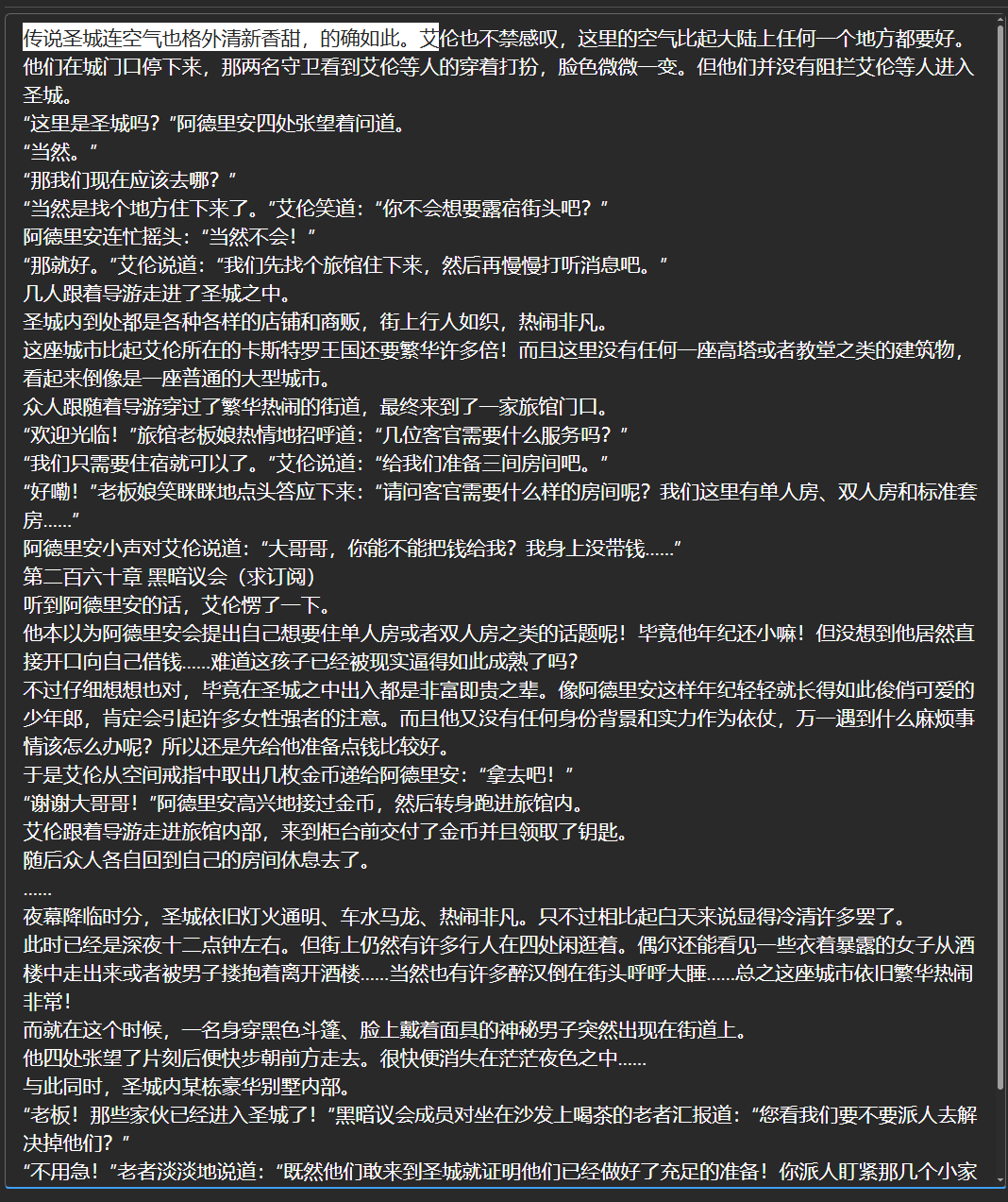
在我们的测试中,RWKV-6-World-7B-v3 模型的中文小说写作能力比之前发布的 RWKV-6-7B-v2.1-ChnNovel 中文小说微调模型更好。
下图是输入传说圣城连空气也格外清新香甜,的确如此。艾作为 prompt,RWKV-6-World-7B-v3 模型的续写结果:
代码相关的长对话
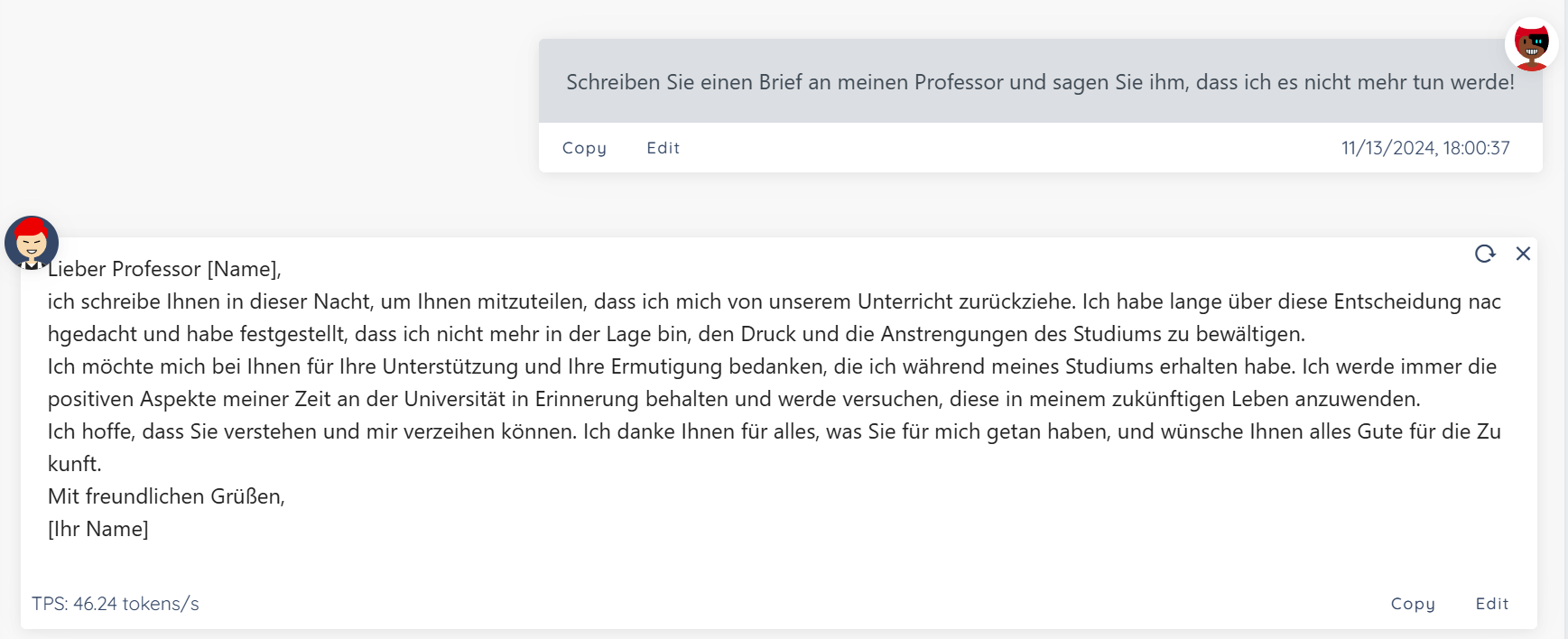
撰写德语邮件
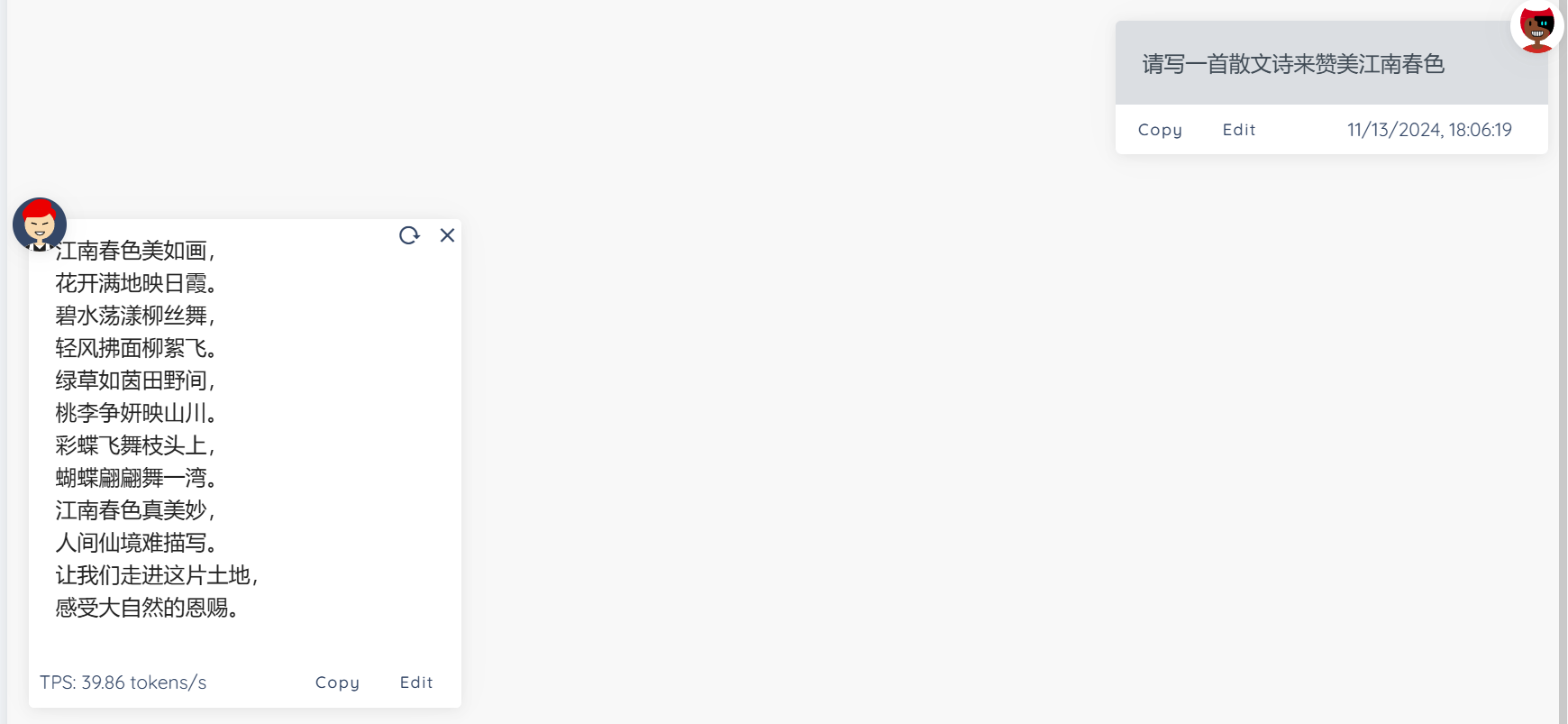
写散文诗
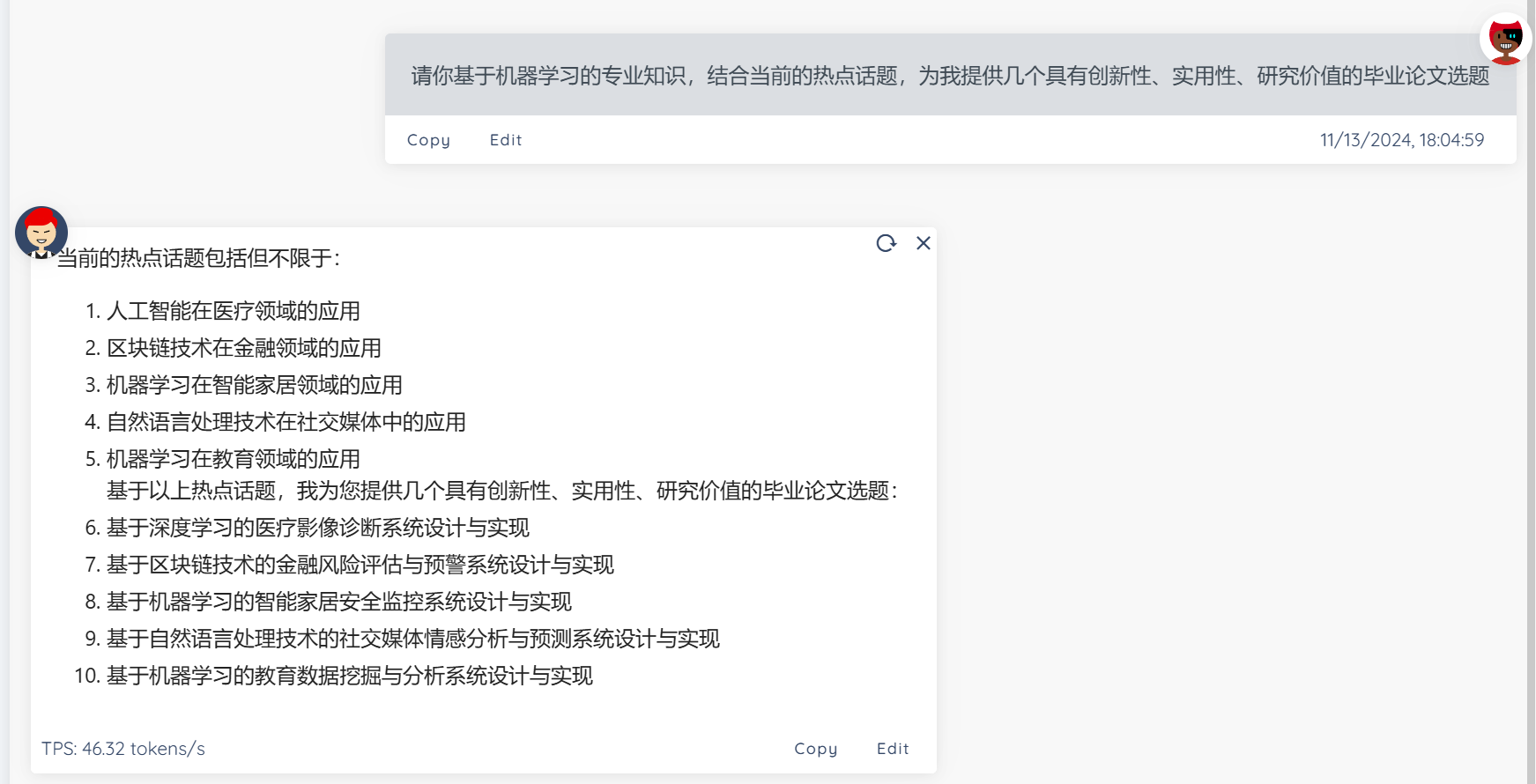
提供论文主题建议
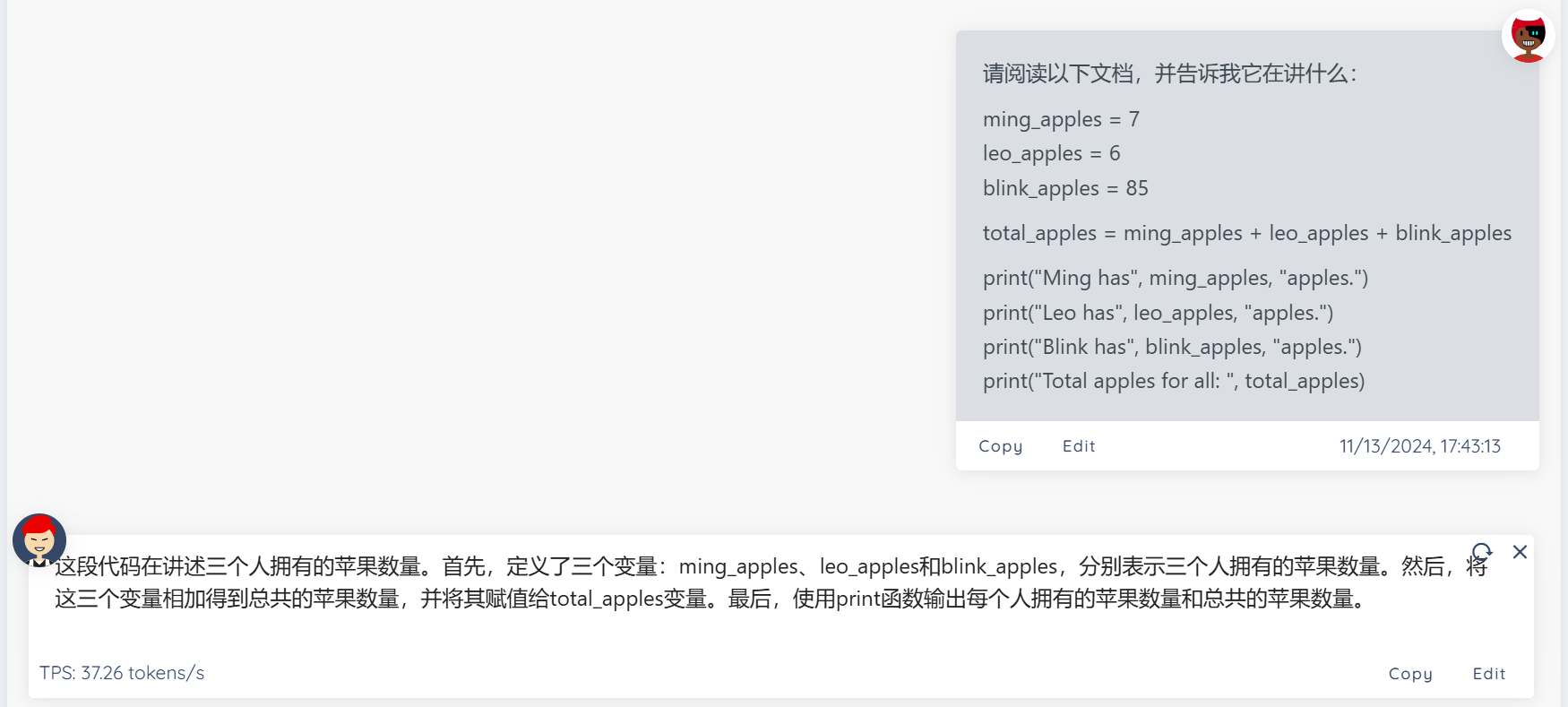
解释代码
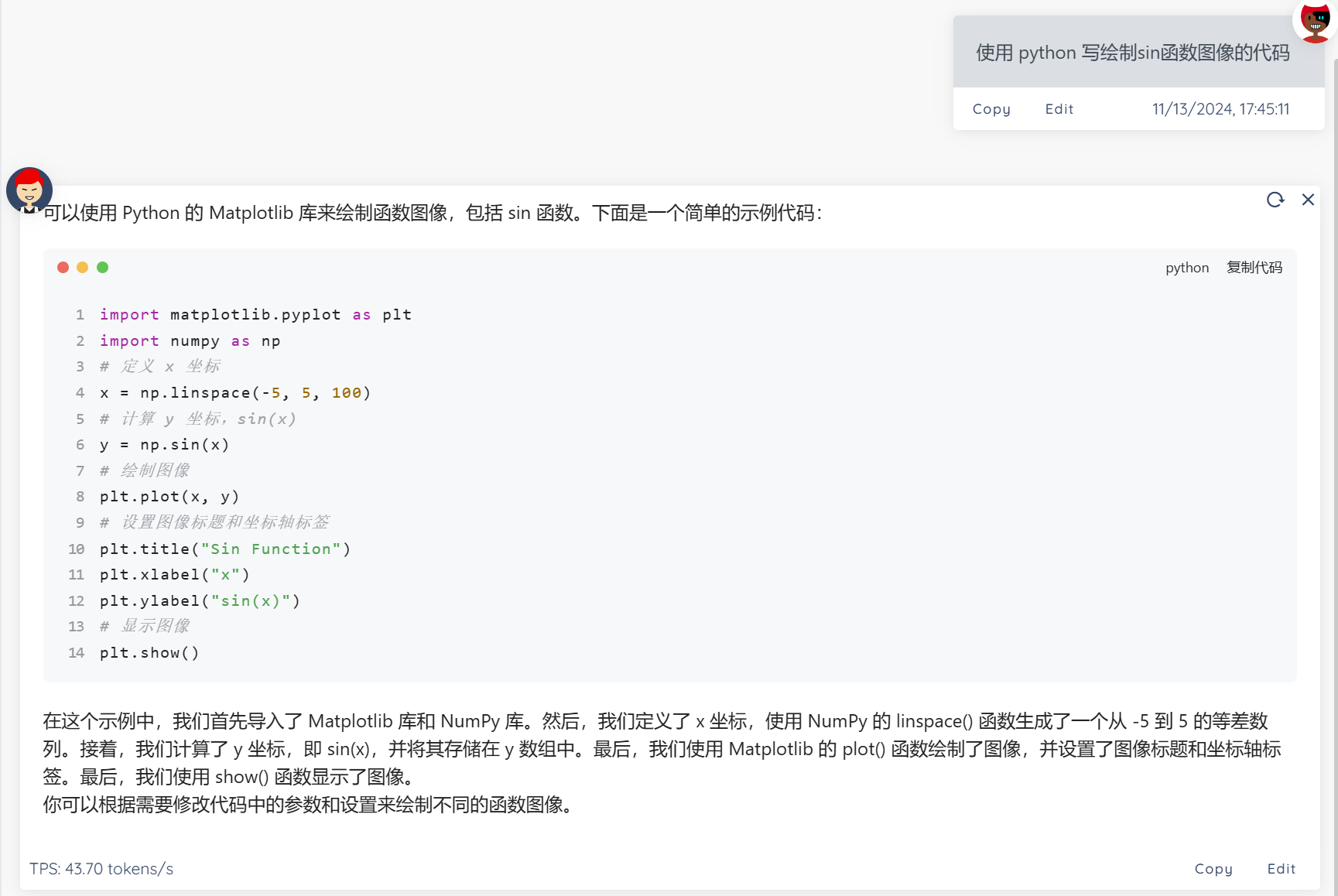
编写 python 代码
不作弊的 RWKV 模型
值得强调的是,我们在训练 RWKV 模型时并未使用 annealing 之类的刷榜技巧来提高 RWKV 的测评成绩。因此 RWKV 模型的实际能力要比它的各种评分排行更强,很适合作为微调的基底模型。
RWKV 模型在某些下游任务可能表现欠佳,这是因为目前开源发布的 RWKV 模型均为基底模型(base model)。基底模型具备一定的指令和对话能力,但为了保持其通用性和泛化能力,RWKV 基底模型未进行任何对齐,也未针对某类任务做优化。
因此,基底模型在特定任务上的表现,并不能代表 RWKV 模型的最优水准。
如果希望 RWKV 模型在某种类型的任务上表现良好且稳定,建议使用对应任务的数据集对 RWKV 模型进行微调训练。
我们已经发布了一些 RWKV 模型的微调训练教程,详情可查看 RWKV 中文文档 – RWKV 微调教程 。
RWKV 模型介绍
RWKV 是一种创新的深度学习网络架构,它将 Transformer 与 RNN 各自的优点相结合,同时实现高度并行化训练与高效推理。
RWKV 模型架构论文:
加入 RWKV 社区
欢迎大家加入 RWKV 社区,可以从 RWKV 中文官网了解 RWKV 模型,也可以加入我们的 QQ 频道和群聊,一起探讨 RWKV 模型。
未经允许不得转载:岩猫星空网 » RWKV-6-World-7B-v3 模型正式开源发布,新增 3.1T 训练数据