
 岩猫星空网
岩猫星空网
通义千问团队开源音频语言模型 Qwen2-Audio。这是 Qwen-Audio 的下一代版本,它能够接受音频和文本输入,并生成文本输出。具有以下特点:
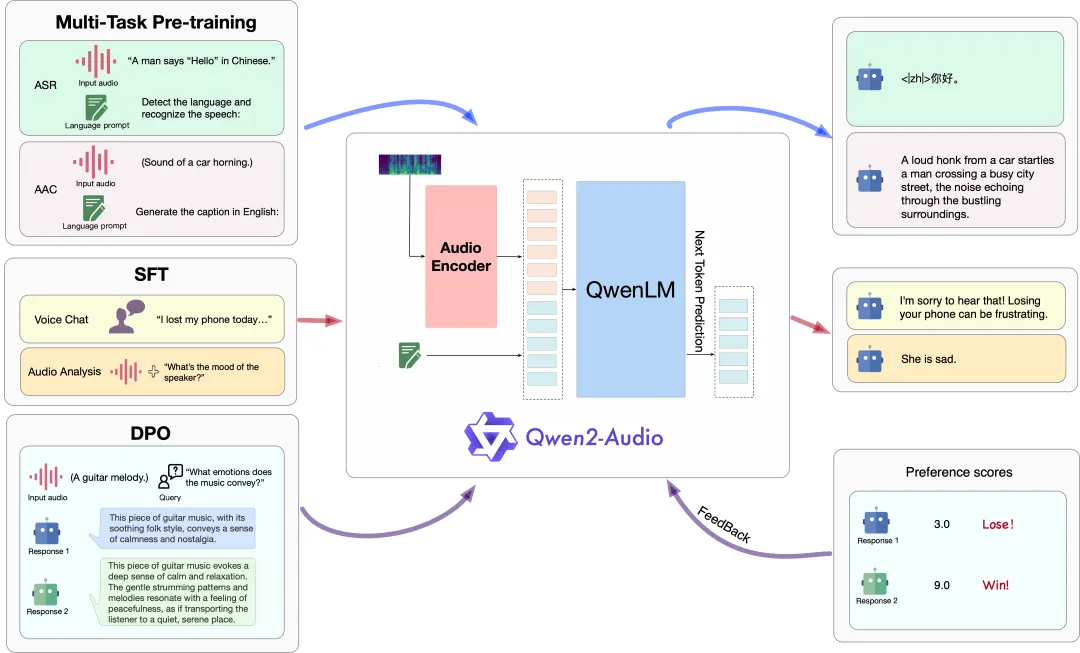
Qwen2-Audio的模型结构包含一个Qwen大语言模型和一个音频编码器。在预训练阶段,依次进行ASR、AAC等多任务预训练以实现音频与语言的对齐,接着通过SFT(监督微调) 强化模型处理下游任务的能力,再通过 DPO(直接偏好优化)方法加强模型与人类偏好的对齐。
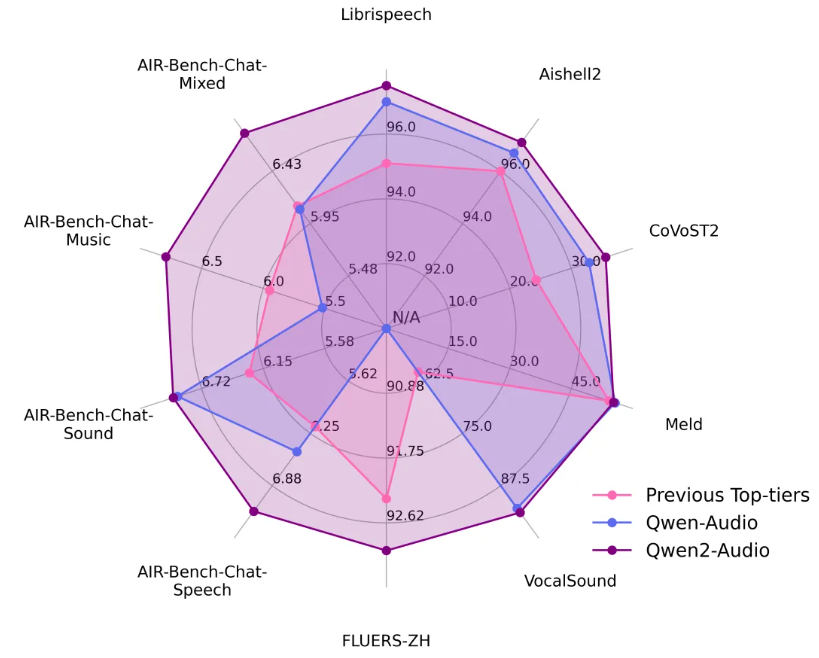
目前通义团队同步开源了基础模型 Qwen2-Audio-7B 及其指令跟随版本 Qwen2-Audio-7B-Instruct。
未经允许不得转载:岩猫星空网 » 阿里通义开源音频语言模型 Qwen2-Audio







