
 岩猫星空网
岩猫星空网中文大模型测评基准SuperCLUE发布2024上半年报告,披露针对国内外33个大模型的综合测评结果。
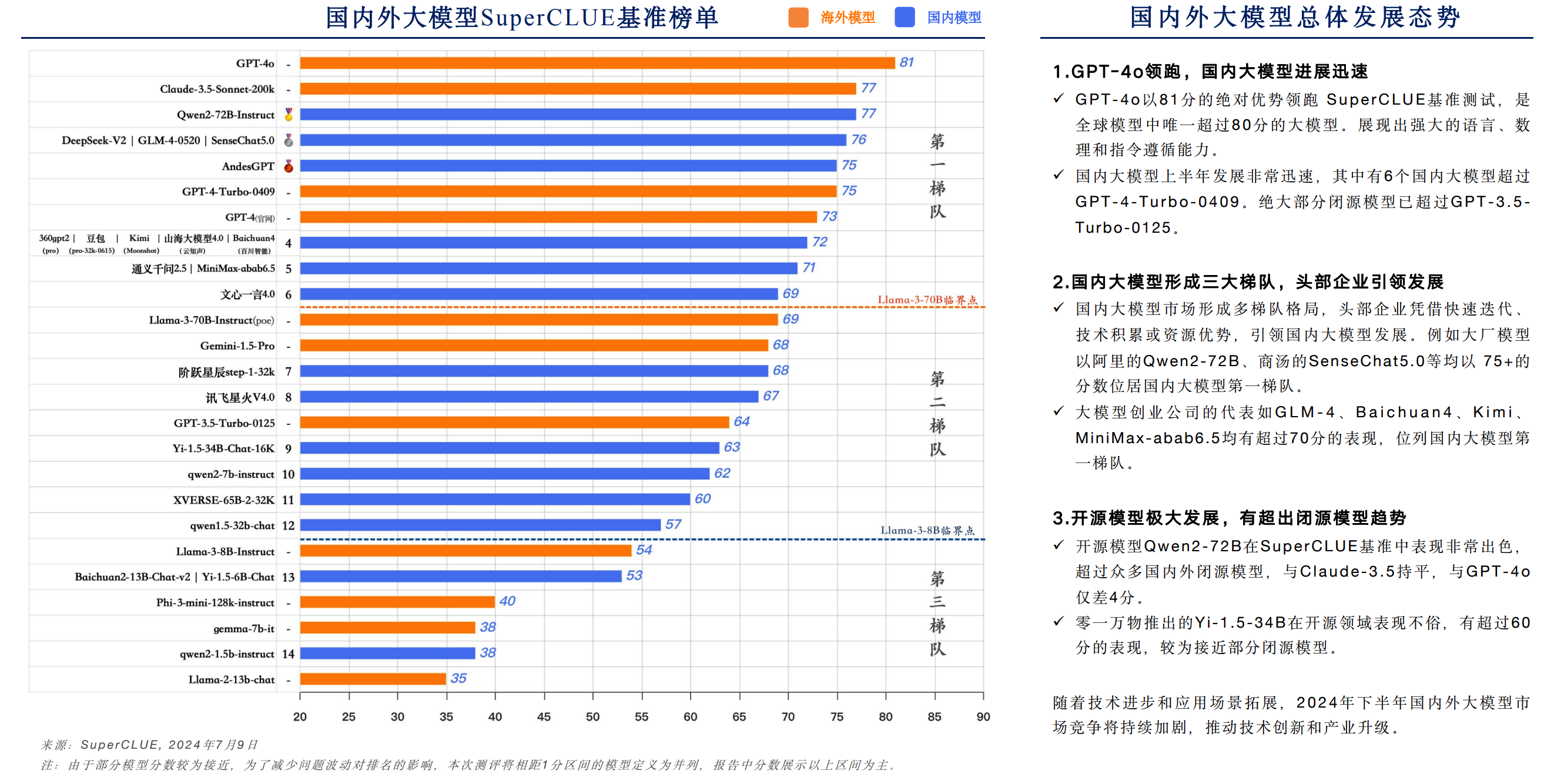
从代表通用能力的一级总分来看,OpenAI的GPT-4o以81分高居榜首,Claude-3.5-Sonnet与通义千问开源模型Qwen2-72B-Instruct并列第二,得分均为77。
通义千问(Qwen2-72B)既是排名最高的中国大模型,也是全球最强的开源大模型,性能超越文心一言4.0、讯飞星火V4.0、Llama-3-70B等开闭源大模型。
SuperCLUE报告认为通义千问“超过众多国内外闭源模型”,“引领全球的开源生态”。
中文大模型基准SuperCLUE介绍
中文语言理解测评基准CLUE(The Chinese Language Understanding Evaluation)是致力于科学、客观、中立的语言模型评测基准,发起于2019年。陆续推出CLUE、FewCLUE、KgCLUE、DataCLUE等广为引用的测评基准。
SuperCLUE是大模型时代CLUE基准的发展和延续。聚焦于通用大模型的综合性测评。SuperCLUE根据多年的测评经验,基于通用大模型在学术、产业与用户侧的广泛应用,构建了多层次、多维度的综合性测评基准。
来源:https://mp.weixin.qq.com/s/Ke18lStd_hkdM8gXOc6dag
《中文大模型基准评测2024上半年报告》
未经允许不得转载:岩猫星空网 » 中文大模型基准测评上半年报告:GPT-4o 排名第一、通义千问“国服最强”







