
 岩猫星空网
岩猫星空网StarRocks 3.3 的发布标志着 Lakehouse 架构在数据分析领域迈向了一个新的高度。作为下一代 Lakehouse 架构的代表,StarRocks 3.3 在稳定性、计算性能、缓存设计、物化视图、存储优化和 Lakehouse 生态系统等方面进行了全方位的优化和创新。本文将逐一介绍 StarRocks 3.3 的这些新特性,带你深入了解这款强大的数据分析工具如何提升你的数据处理效率和分析能力。
成熟稳定:全面提升的成熟度级别和大查询稳定性
为了帮助用户更好地理解和使用新功能,StarRocks 3.3 对各项新特性进行了成熟度级别的划分,并采用了更清晰的标记体系:Experimental(实验性质)、Preview(公测阶段)和 GA(生产可用)。这种分级体系使用户能够根据功能的成熟度来决定是否在生产环境中使用。
此外,为了进一步提升用户体验,我们针对数据湖分析、存算分离和物化视图等关键功能提供了更完整的产品能力边界和版本对照文档,方便用户理解和使用。
StarRocks 3.3 针对大查询、数据压缩和数据湖场景的内存占用进行了显著优化。通过 GA 级别的算子落盘能力(Spill to Disk),有效地优化了复杂查询的内存占用和 Spill 调度,确保大查询能够稳定执行而不会导致内存溢出(OOM)。此外,支持 Colocate Group Execution,通过分阶段执行 Colocated 表上的查询,大幅降低 Join 和 Agg 算子在执行时的内存占用,从而显著提升大查询的稳定性。
性能提升:新架构,新台阶,新场景
StarRocks 3.3 的发布不仅提升了基础性能,更在真实场景中的性能优化上迈上了新台阶。我们不仅仅拘泥于Benchmark 测试的成绩,而是专注于在实际应用中的性能提升。
首先,在新架构性能优化方面,StarRocks 对 ARM 架构进行了大幅优化,相比 x86 平均成本降低 20%,同时查询性能提升20%,使其成为与 x86 架构同等重要的一等公民。 在 AWS Graviton 实例上的测试中,ARM 架构的性能提升显著:在 SSB 100G 测试中,ARM 比 x86 快 11%;在Clickbench 测试中,ARM 比 x86 快 39%;在 TPCH 100G 测试中,ARM 比 x86 快 13%;在 TPCDS 100G 测试中,ARM 比 x86 快 35%。

在数据湖性能优化方面,StarRocks 3.3 提升了 Scan 性能,通过对 Page Index 的优化显著减少了 Scan 的数据规模,降低了 Page 多读的情况。此外,元数据性能也有了突破,显著提升了整体的处理效率。
针对特定场景的性能提升,StarRocks 3.3 进行了多方面的优化:
缓存设计: Lakehouse 架构的最后一块拼图
在 Lakehouse 架构中,缓存设计是实现高效数据处理的关键一环。对于存算分离架构来说,缓存的重要性不言而喻。无论是 Hive、Iceberg、Paimon 等外表,还是 StarRocks 存算分离的内表,缓存命中率的高低直接影响性能的优劣。在缓存命中情况下,性能已经能够追平存算一体的架构,但如何合理、稳定地将热数据保存在缓存中却是一大挑战。
StarRocks 原生开发的缓存功能为用户提供了开箱即用的便捷体验。无需复杂的配置,用户即可利用强大的缓存机制提升数据处理性能。StarRocks 3.3 通过一系列创新功能显著提升了缓存的能力:
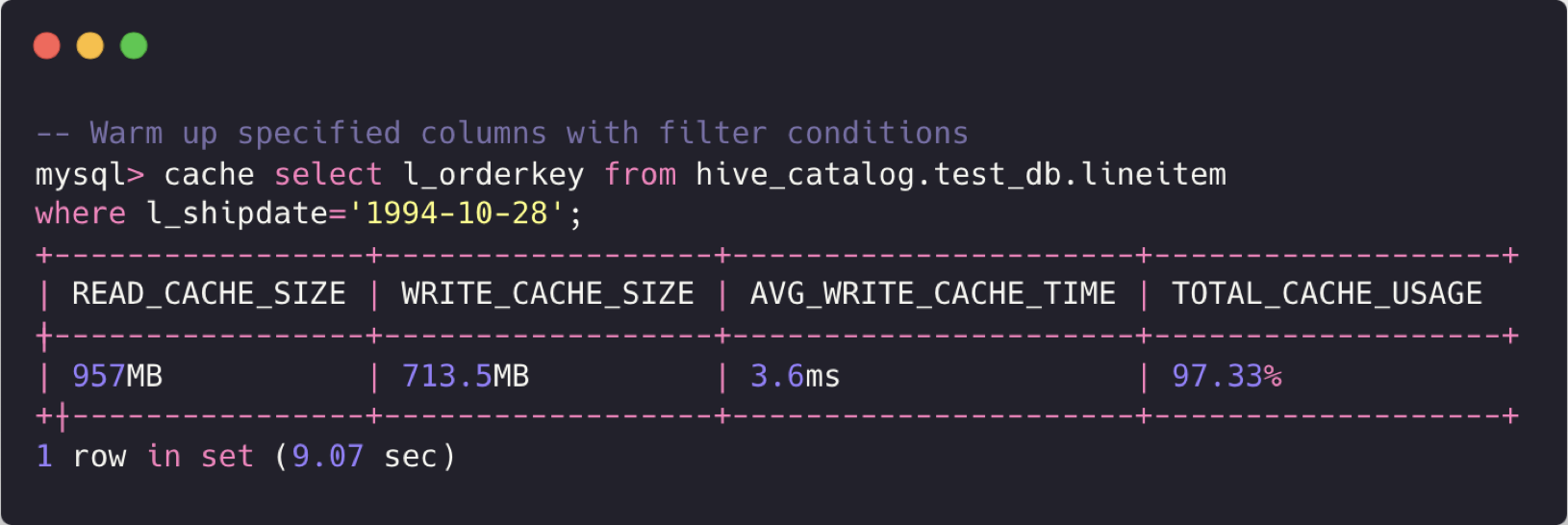
在存算分离集群中,StarRocks 3.3 还适配了AWS Express One Zone Storage,大幅提升了读写性能,为未来的全局缓存带来了全新的可能性。
此外,在缓存无法命中或者不希望使用缓存的场景下,冷查性能也得到了显著提升。主要通过优化 tablet 的并行扫描,以及对小 I/O 的自动合并,使得即使在没有缓存支持的情况下,查询性能依然表现优异。
物化视图:连接湖仓的高效纽带
物化视图作为 StarRocks 的核心能力,也是连接 Open lake format 和 StarRocks 内表的纽带。通过外表物化视图,可以透明地为数据湖上的查询进行加速,在保证 single source of truth 的同时,降低数据加工的复杂度。
在 3.3 版本中,我们又进一步做了一些重要优化:
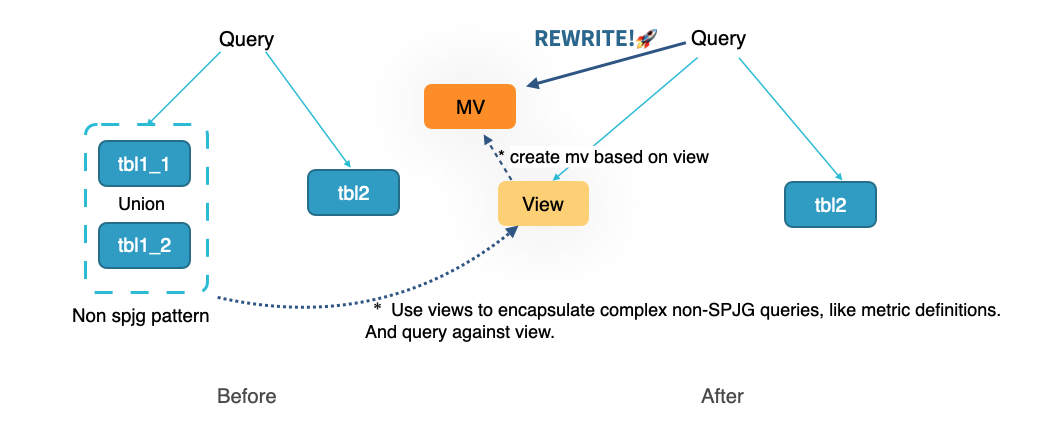
开启物化视图属性 transparent_mv_rewrite_mode 后,当用户直接查询物化视图时,StarRocks 会自动改写查询,将已经刷新的物化视图分区中的数据和未刷新分区对应的原始数据做自动 Union 合并。
存储优化:更高效易用的数据管理
StarRocks 3.3 在存储优化与易用性提升方面做出了诸多改进,进一步增强了系统的性能和用户体验。
首先,StarRocks 3.3 提升了 FE 的可观测性和锁机制优化。提供了详细的内存使用指标,让用户可以更好地管理和监控资源。同时,引入了锁管理器(Lock Manager),实现对元数据锁的集中管理,将元数据锁的粒度从库级别细化为表级别。 这种细化显著提高了导入和查询的并发性能,在 100 并发的导入场景下,导入耗时减少了 35%。
为了增强建表语句的清晰度,StarRocks 3.3 支持了 ORDER BY 语法,使得建表操作更加直观和简洁。此外,还增加了对重命名列(Rename Column)的支持(版本 3.3.1),进一步提升了数据管理的灵活性。
在存储效率方面,StarRocks 3.3 优化了非字符串标量类型数据的存储方式,存储空间下降了 12%。这不仅降低了存储成本,也提升了数据读取的效率。
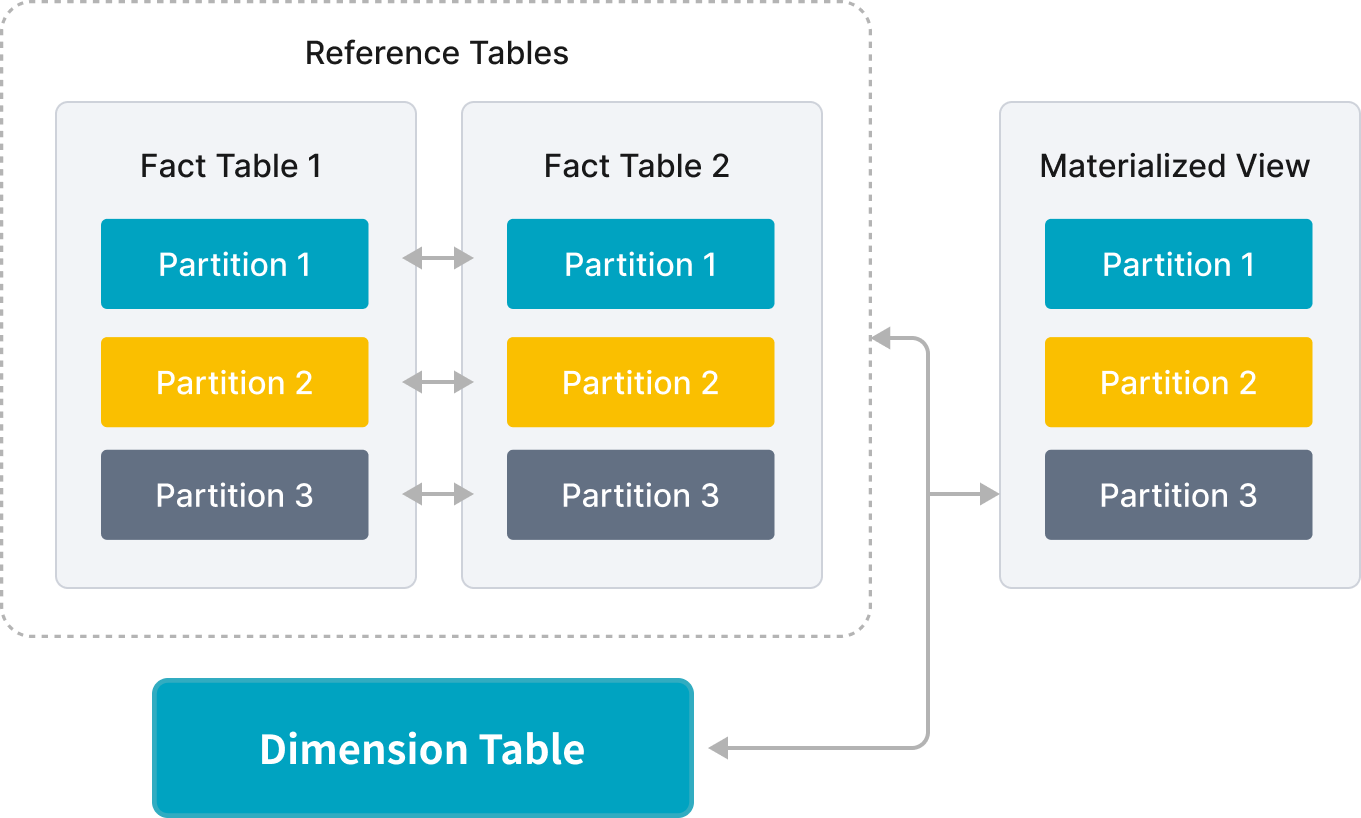
针对主键表,StarRocks 3.3 实施了多项优化:
生态支持:Lakehouse 扩展与集成
Hive 生态支持 :在3.3版本中,StarRocks 支持对 ORC 和 Text 文件的写入能力。 单 sink 算子的写入性能达到了 Trino 的 2 倍。
Iceberg 生态支持 :StarRocks 3.3 大幅重构了 Iceberg 元数据查询模块,通过分布式元数据读取提升对 Avro 格式文件的解析性能,避免原生 SDK 的单点瓶颈,对小规模的元数据通过 manifest 缓存来降低重复 I/O,从而大幅提升了Iceberg 的元数据访问性能。同时,增加了对 V2 表 equality delete 的支持,使用户能够高效分析使用 Flink 写入的Iceberg upsert 数据。此外,还引入了对 Iceberg 视图(Iceberg View)的查询支持,使得数据管理和查询更加便捷和直观。
Paimon 生态支持 :StarRocks 3.3 现已全面支持 Paimon 生态系统,包括对最新的 delete vector 的支持、Paimon 系统表的集成以及 scan range 调度的优化。通过这些改进,用户可以更高效地管理和查询 Paimon 中的数据,实现更灵活的数据处理和分析。
ClickHouse 和 Kudu 生态支持 :为了方便用户从 Clickhouse 迁移到 StarRocks,社区贡献了专用的迁移工具,使得数据迁移过程更加平滑和高效。此外,StarRocks 还支持 ClickHouse 和 Kudu 的 Catalog 功能,使得用户可以更便捷地在这两种数据库和 StarRocks 之间进行数据管理和查询。
总结:成熟的 Lakehouse 架构
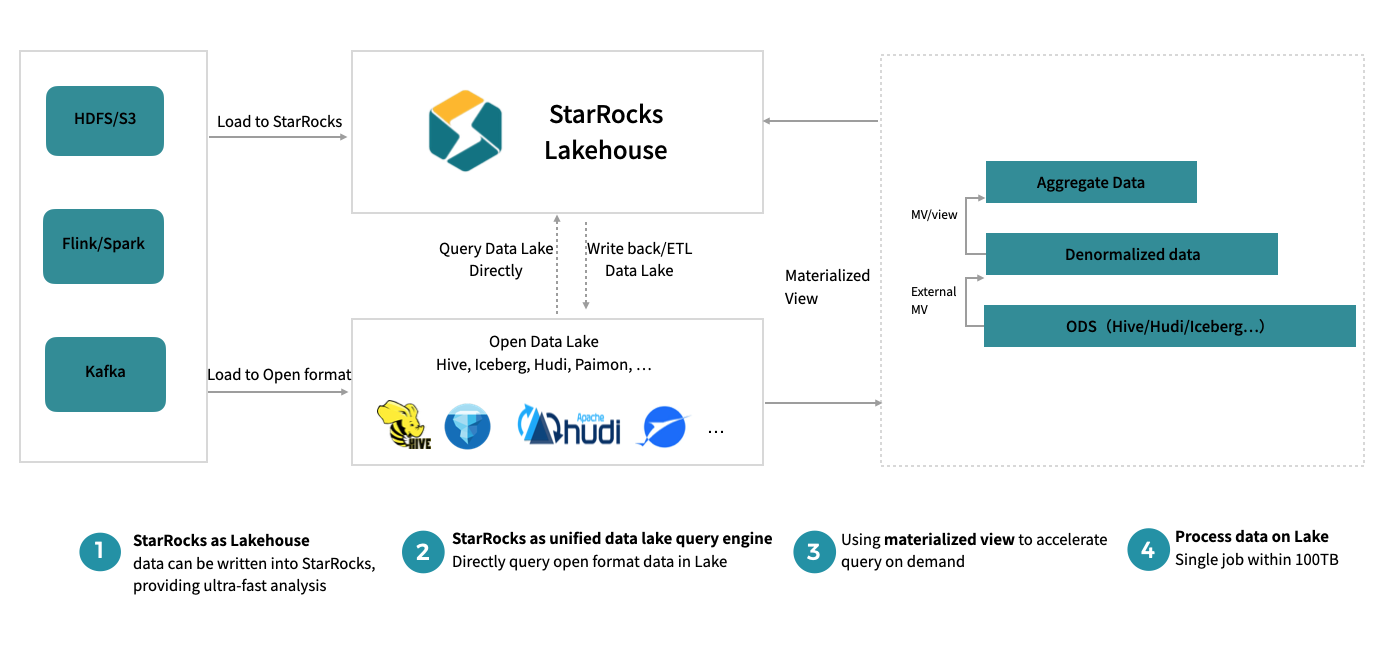
StarRocks 正在积极向成熟的湖仓架构升级,不仅增强了与开放湖格式的兼容性,还显著提升了湖的写入性能。在数仓功能上,它进一步加强了索引和半结构化数据处理的性能,同时,存算分离架构成为更受青睐的成熟解决方案。
此外,大查询和 ETL 任务的稳定性的提高,为批处理的能力打下基础。这些进步共同推动了 StarRocks 向一套架构,满足所有的分析需求的"One data, All Analytics"愿景的迈进。
更详细的 feature 介绍参考:
Release note: https://docs.mirrorship.cn/zh/releasenotes/release-3.3/
下载: https://www.mirrorship.cn/zh-CN/download/starrocks
直播回放 :https://www.bilibili.com/video/BV1F7421d72D/
更多交流,联系我们:https://wx.focussend.com/weComLink/mobileQrCodeLink/33412/2b42f
未经允许不得转载:岩猫星空网 » StarRocks 3.3 重磅发布,Lakehouse 架构发展进入快车道!







