
 岩猫星空网
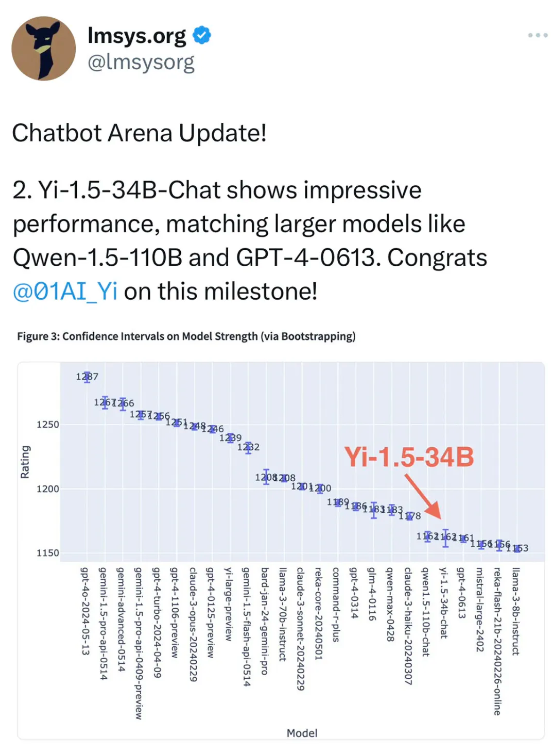
岩猫星空网零一万物旗下 Yi-1.5-34B 近日在 Chatbot Arena 总榜中以 1162 的 ELO 积分超越了 GPT-4-0613、Mistral-large-2402 等知名海外厂商发布的大尺寸模型,与 Qwen1.5-110B-Chat 并列第20名(2024.6.6)。
在中文分榜上,Yi-1.5-34B 以 1274 的 ELO 积分跻身世界前十,同时在采用 Apache 2.0 许可协议的模型中位居第一(2024.6.6)。零一万物称其可谓是开源界中小模型中最能打的羽量级选手,LMSYS 评测组织方也发帖进行了恭贺。

相比 7B、13B 等尺寸,34B 模型具备更优越的知识容量、下游任务的容纳能力,也达到了大模型 “涌现”的门槛;而比起 70B 以上的参数量,34B 是单卡推理可接受的模型尺寸的上限,经过量化的模型可以在一张消费级显卡(如4090)上进行高效率的推理。因此,34B 的模型尺寸在开源社区属于稀缺的“黄金比例”尺寸。也是基于这一认知,零一万物正式开源的首款预训练大模型就是 Yi-34B。
相较于去年 11 月的开源版本,这次的 Yi-1.5-34B 在保持原 Yi 系列模型优秀的通用语言能力的前提下,通过增量训练 500B 高质量 token,大幅提高了数学逻辑、代码能力。与迭代前的 Yi-34B 相比, Yi-1.5-34B 在 LMSYS 总榜上的 ELO 积分大幅提升,从 Yi-34B 的 1111 增至 1162(2024.6.6);在“Coding”分榜上,Yi-1.5-34B 的 ELO 积分也由上一版本的 1108 增至 1161(2024.6.6)。
此外,在MixEval、MMLU-Pro、WildBench 等其他评测集上,Yi-1.5-34B 也取得了优于同量级模型的成绩。在 WildBench 排名中,Yi-1.5-34B 的表现更是优于更大参数量级的 Qwen2-72B-Instruct(2024.6.6)。
零一万物开源负责人林旅强表示,“我们相信开源开发者生态依赖于口碑,国内生态需要更多中立角色,以开发者为中心进行良性竞争。海外开发者更注重体验,无论是使用开源模型还是 API,都追求良好体验。我们真诚地希望,升级后的 Yi-1.5 系列开源模型能够为大家带来真正的价值。”
未经允许不得转载:岩猫星空网 » 零一万物 Yi-1.5-34B 开源小尺寸打平千亿模型







